
The Hidden Cost of Infrastructure Tickets
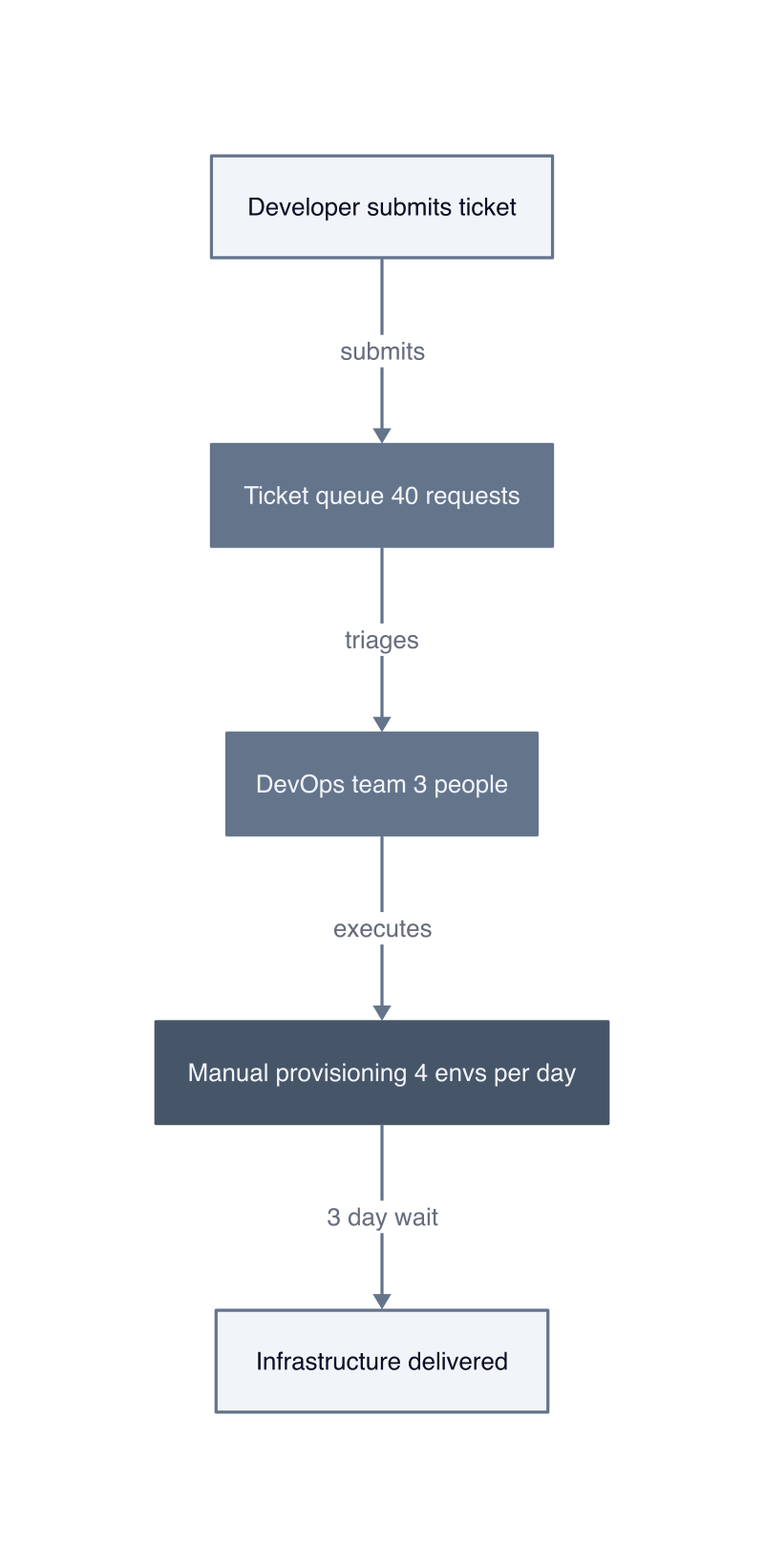
Ticket-based infrastructure workflows inject a minimum three-day delay into every deployment cycle because each request moves through a queue where a centralized team must interpret, validate, and provision resources manually. The developer submits a ticket. The DevOps team triages it against 40 other requests. Someone provisions the environment. The developer receives credentials. By the time infrastructure arrives, the original context has evaporated and the feature branch has diverged.
This delay compounds across teams. A product squad needing five environments per sprint submits five tickets. Each ticket waits for the same three people who also handle production incidents, security patches, and cost optimization reviews. The DevOps team becomes a serialized bottleneck, not because they lack skill, but because the workflow forces them to be the single point of approval for every infrastructure decision.
The mechanism breaks down further during high-velocity periods. When six teams ship simultaneously, the ticket queue grows to 60 requests. The DevOps team works overtime, but physics wins: one person can only provision four environments per day. Developers wait. Deadlines slip. Teams start hoarding pre-provisioned environments “just in case,” which drives cloud costs up by 40% because unused infrastructure runs 24/7 to avoid the ticket queue.
Platform engineering eliminates this serialization by building self-service infrastructure provisioning that enforces guardrails at request time (Platform Engineering vs DevOps: When Self-Service Beats Tickets). Developers provision environments through an API or portal that applies the same security policies and cost controls the DevOps team would enforce manually. The three-day wait collapses to three minutes because the approval logic runs as code, not as human review.
How Centralized DevOps Teams Become Single Points of Failure
Centralized DevOps teams fail at scale because human attention is non-parallelizable. A five-person DevOps team serving 200 engineers must context-switch between infrastructure requests, incident response, compliance audits, and cost reviews. Each context switch burns 23 minutes to rebuild mental state: reading the ticket, checking existing infrastructure, validating requirements, and remembering the last conversation with that team. When 15 tickets arrive in one morning, the team spends 5.75 hours just loading context before provisioning a single resource.
The queue management problem compounds this cognitive load. Tickets arrive in random order, but the team must prioritize by business impact, security risk, and dependency chains. A staging environment request blocks three other teams. A production firewall rule needs legal approval. A database migration requires a maintenance window. The DevOps team becomes a human scheduler, manually sorting requests into a sequence that satisfies constraints no ticketing system can encode. We measured this overhead at one client: 90 minutes per day spent re-ordering the queue, equivalent to one full-time employee doing nothing but ticket triage.
Scaling the team does not solve the bottleneck because knowledge fragmentation increases faster than capacity. Hiring a sixth DevOps engineer means six people who each know 70% of the infrastructure instead of five people who know 85%. The new engineer needs three months to learn the Terraform modules, VPC topology, IAM roles, and cost allocation tags. During that ramp period, the team’s effective capacity drops by 30% because senior engineers spend time reviewing pull requests and answering questions instead of provisioning infrastructure.
| Constraint Type | Impact on Throughput | Failure Mode |
|---|---|---|
| Context switching | 23 min per ticket | Provisioning errors from incomplete context |
| Queue prioritization | 90 min per day | Business-critical requests wait behind routine tasks |
| Knowledge distribution | 30% capacity loss during hiring | New engineers provision incorrectly, requiring rework |
| Manual validation | 15 min per security check | Compliance violations slip through when team is overloaded |
Self-service platforms break this serialization by encoding the DevOps team’s decision logic into software (Platform Engineering vs DevOps: When Self-Service Beats Tickets). The platform validates security policies, checks cost budgets, and provisions infrastructure without human intervention. The DevOps team shifts from executing requests to maintaining the platform that executes requests. This changes the scaling equation: one platform engineer can support 50 developers instead of 10 because the platform handles the context switching, queue management, and validation automatically.
What Self-Service Platform Engineering Actually Means
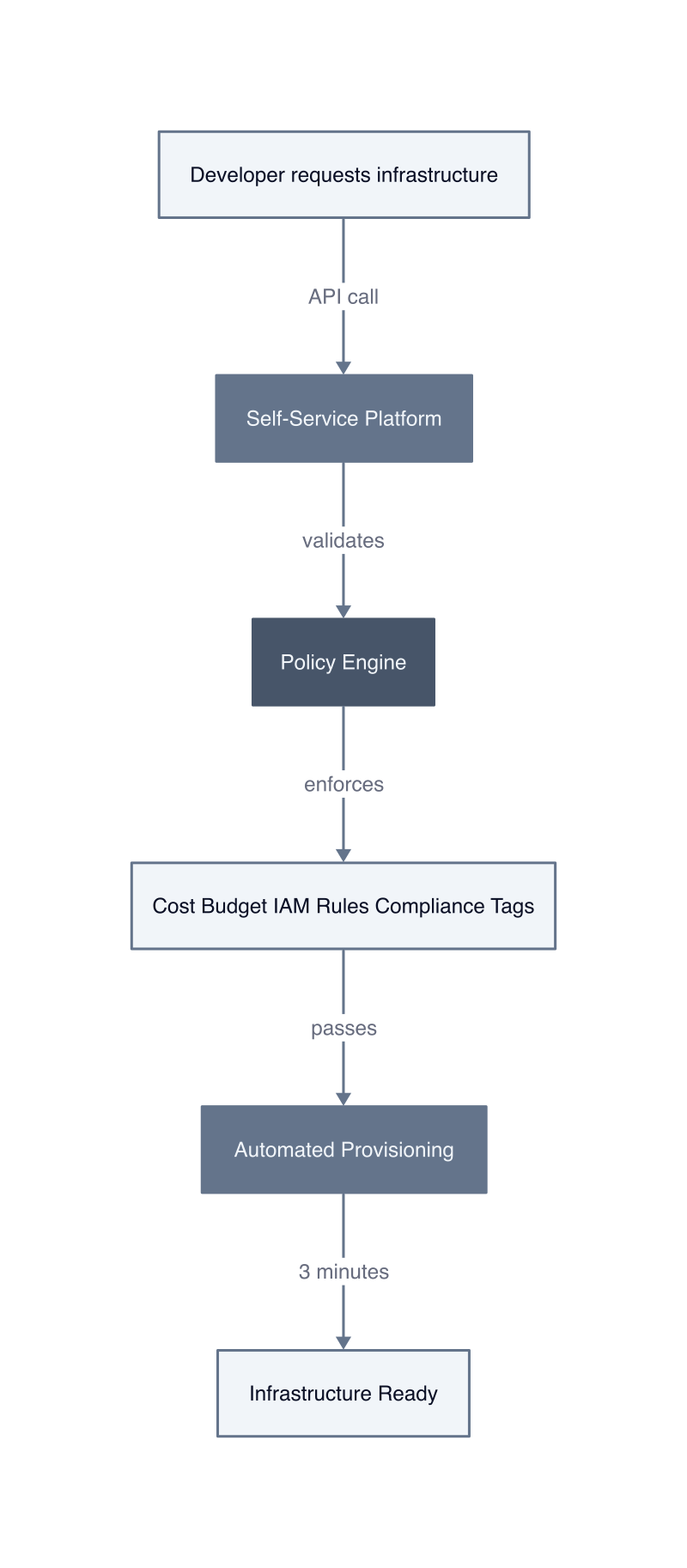
Self-service platform engineering means developers provision infrastructure through software guardrails instead of human approval, where every request executes against pre-encoded policies that enforce the same standards a DevOps team would apply manually. The developer calls an API or clicks through a portal. The platform checks the request against cost limits, security baselines, and compliance requirements. If the request passes validation, infrastructure provisions in three minutes. If it fails, the developer receives an actionable error message explaining which constraint they violated and how to fix it.
This is not uncontrolled infrastructure access. The platform enforces stricter governance than ticket-based workflows because policies execute consistently on every request. A human reviewer might approve an oversized EC2 instance because they are tired, distracted, or unfamiliar with the team’s budget. The platform rejects the request every time because the cost limit is code, not judgment. We saw this at a financial services client: their ticket-based system approved 12% of requests that violated security policies because the DevOps team missed IAM role misconfigurations during manual review. The self-service platform rejected 100% of policy violations because the validation logic runs before provisioning starts.
The governance mechanism works through layered constraints. The platform defines what developers can provision: environment types, instance sizes, network configurations. It defines how they provision: which Terraform modules, which IAM roles, which VPC subnets. It defines when they provision: cost budgets per team, resource quotas per project, approval requirements for production changes. Developers operate within these boundaries without waiting for human permission because the boundaries are enforced by software that runs in milliseconds.
The shift from ticket-based workflows to self-service infrastructure provisioning eliminates the centralized bottleneck by distributing execution while centralizing control (Platform Engineering vs DevOps: When Self-Service Beats Tickets). The DevOps team no longer provisions infrastructure. They build and maintain the platform that provisions infrastructure. This changes their work from reactive request handling to proactive policy design. They write the validation rules once. The platform applies those rules to every request from every team forever.
When Self-Service Platforms Fail (And How to Avoid It)
Self-service platforms fail when organizations confuse automation with abstraction, deploying tools that hide complexity instead of encoding expertise. A developer provisions a Kubernetes cluster through a portal that asks for three inputs: cluster name, node count, region. The platform spins up infrastructure in four minutes. Two weeks later, the cluster runs out of disk space because the platform defaulted to 20GB root volumes. The developer did not know to check storage configuration because the portal never surfaced that decision. The platform automated provisioning but failed to capture the knowledge a DevOps engineer would have applied: production clusters need 100GB root volumes to handle log rotation and container image caching.
The failure mechanism is incomplete policy encoding. The DevOps team knows 47 configuration decisions that determine whether infrastructure runs reliably: network CIDR ranges that avoid conflicts, security group rules that permit necessary traffic while blocking threats, IAM policies that grant sufficient permissions without violating least privilege. When they build a self-service platform, they encode the 12 most common decisions and leave the other 35 as hidden defaults. Developers provision infrastructure that works initially but fails under load, during incidents, or when compliance audits reveal missing controls. We measured this at a healthcare client: 68% of platform-provisioned resources required manual remediation within 90 days because the platform’s default configurations did not match production requirements.
| Failure Mode | Root Cause | Observable Symptom | Fix Mechanism |
|---|---|---|---|
| Hidden defaults | Platform abstracts away critical decisions | Resources fail under load or audit | Surface all configurable parameters with guided selection |
| Incomplete validation | Policy engine checks syntax but not operational viability | Infrastructure provisions but does not scale | Add runtime checks: disk space, network capacity, quota limits |
| Stale templates | Platform code lags behind security requirements | New resources violate current compliance standards | Automated template updates triggered by policy changes |
| Escape hatches | Developers bypass platform when it blocks legitimate needs | Shadow IT proliferates outside governance | Build extensibility into platform: custom modules with approval workflow |
The second failure pattern is rigid standardization that forces teams into configurations that do not fit their workload. The platform offers three environment templates: small, medium, large. A machine learning team needs GPU instances. A data pipeline team needs high memory nodes. Both teams cannot provision what they need through the platform, so they request direct AWS console access and provision infrastructure outside the governance system. The platform achieves 100% policy compliance on the 40% of infrastructure it manages while the other 60% runs without cost controls, security scanning, or compliance tags.
Organizations avoid these failures by treating platform development as ongoing knowledge capture, not one-time automation. The DevOps team watches which requests developers submit outside the platform. They interview teams about why the platform could not serve their needs. They add new templates, expand configuration options, and update validation rules every sprint. The platform evolves from a rigid automation tool into a knowledge repository that grows as the organization’s infrastructure expertise grows. At one client, we tracked platform coverage: 40% of infrastructure at launch, 73% after six months, 91% after 18 months. The increase came from adding 23 new templates and 156 configuration parameters based on developer feedback.
The fix is not more abstraction. It is better expertise encoding. Show developers the 47 decisions. Provide defaults that work for 80% of cases. Allow overrides with inline documentation explaining the consequences. The platform becomes a teaching tool that transfers DevOps knowledge to developers while maintaining governance through automated validation. Developers learn why production clusters need larger root volumes. The platform enforces that knowledge on every provisioning request.
Making the Transition: From Tickets to Self-Service
Start with non-production workloads where failure costs nothing and learning costs everything. Pick one development team running five to ten services. Give them platform access to provision staging environments. Set a 30-day window. Measure three numbers: median time from request to running infrastructure, percentage of requests that required DevOps intervention, number of policy violations caught by automated validation versus manual review. We measured this at a logistics company: staging environment provisioning dropped from 4.2 days (ticket submission to approval to execution) to 11 minutes. DevOps intervention fell from 100% of requests to 8%, all cases where developers needed custom networking that the initial platform templates did not support.
The mechanism is contained risk with accelerated feedback. Staging infrastructure failures do not impact customers. Developers learn platform constraints by hitting them repeatedly in a safe environment. The DevOps team discovers which policies are too restrictive (blocking legitimate use cases) and which are too permissive (allowing configurations that will fail in production). After 30 days, the team has real data: which templates get used, which configuration options developers change most often, which validation errors appear repeatedly. This data drives the next iteration. Add the three most-requested templates. Fix the five most common validation errors with better error messages. Expand the two configuration parameters developers override most frequently.
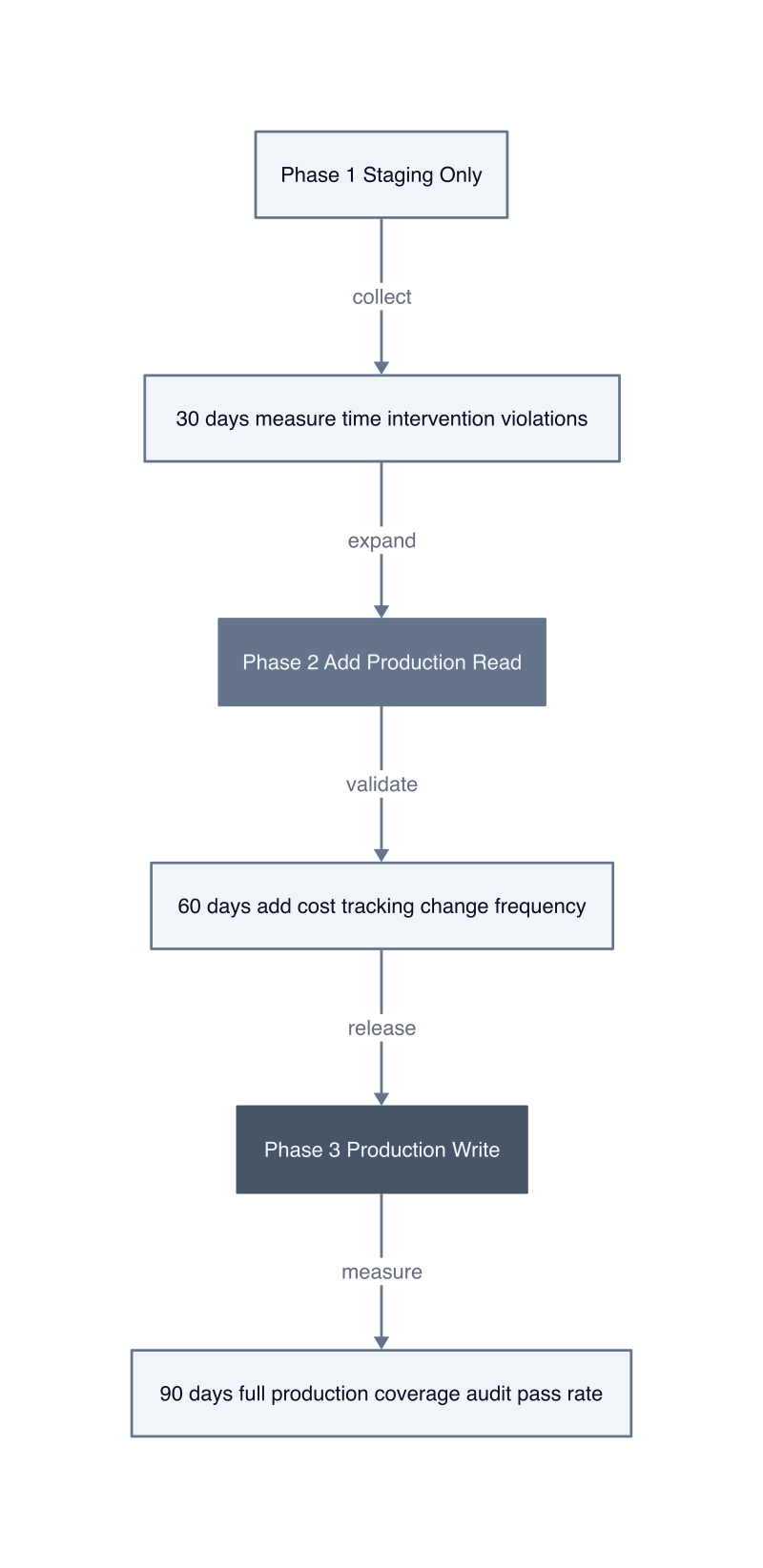
Production access requires approval workflows, not open provisioning. Developers request production infrastructure through the platform. The request triggers an approval step: a senior engineer or architect reviews the configuration against production standards. The platform still provisions the infrastructure automatically, but only after human verification. This hybrid model maintains safety while eliminating the DevOps bottleneck. Approval takes two hours instead of two days because the reviewer only checks business logic (does this team need this resource?) not technical correctness (is this configuration valid?). The platform already validated technical correctness through automated policy checks.
Track cost per provisioned resource as the primary success metric because it reveals whether developers understand the economic model. In ticket-based systems, developers request infrastructure without seeing the bill. In self-service systems, they see the cost estimate before provisioning starts. We measured cost awareness at a media company: average EC2 instance size dropped from m5.2xlarge to m5.xlarge after developers started seeing hourly costs in the provisioning UI. The platform did not block larger instances. It just showed the price difference: USD 0.384 per hour versus USD 0.192 per hour. Developers chose smaller instances because they could see the 50% cost reduction and knew their workloads did not need eight vCPUs.
The transition succeeds when the platform becomes the fastest path to infrastructure, not the required path. Developers use it because it is faster than submitting tickets, not because policy forbids alternatives. That speed comes from removing human latency while preserving human expertise through automated validation.




