
The Optimization Illusion: Why Cloud Savings Don’t Last
Cloud cost optimizations expire. Not because engineers lose discipline, but because the infrastructure beneath every savings decision keeps moving. New services launch, teams grow, deployment frequency increases, and the right-sized cluster from last quarter becomes the undersized cluster this quarter. The savings number in the board deck is real on day one. By day 90, the gap between that number and actual spend has quietly reopened.
This is the Savings Decay Curve: the predictable erosion of realized cloud savings when no active mechanism holds the optimized state in place. It is not a failure of intent. It is a structural property of cloud infrastructure, which is designed to scale on demand and therefore to consume more resources as demand grows. Optimization without a retention mechanism is a point-in-time fix applied to a continuously moving target.
We measured this pattern across multiple production environments. The teams that ran quarterly rightsizing exercises saw their savings erode within 45 to 60 days of the next deployment cycle. The mechanism is straightforward: engineers provision new workloads using default resource requests, not the tuned values from the last optimization pass. Default requests are almost always overprovisioned because the engineer writing the manifest has no feedback loop telling them what the workload actually consumed in staging.
Structural drift. Cloud environments accumulate waste through normal engineering activity, not negligence. Each new microservice, each autoscaling policy set to “safe” defaults, each forgotten staging environment running at full capacity adds to the baseline. After 30 days of unchecked growth, the optimized baseline is no longer the actual baseline.
The point-in-time trap. A one-time rightsizing audit produces a savings figure that is accurate for the infrastructure state at audit time. That state changes with every deployment. Without a continuous enforcement layer, the audit result decays at the same rate as the deployment cadence increases.
Accountability diffusion. Cost ownership erodes as teams scale. When five engineers share a namespace, no single engineer owns the resource budget. Shared ownership produces no ownership in practice, because the cost of overprovisioning is invisible to the team incurring it.
The fix is not more frequent audits. The fix is a set of levers that make the optimized state the default state, enforced at the point where engineers make provisioning decisions. That is the structural difference between a savings event and a savings floor.
How Fast Do Savings Decay, and What Drives the Erosion?
Savings decay follows a predictable sequence, and the sequence accelerates with every layer of organizational complexity added on top of a cloud environment.
The erosion begins at the provisioning layer. Engineers writing new deployment manifests pull from internal templates, and those templates carry the resource requests that were “safe” at the time someone last edited them. Nobody updates the template after a rightsizing pass because the rightsizing pass produces a spreadsheet, not a policy. Within the first deployment week after an optimization exercise, new workloads enter production already overprovisioned. The savings floor drops before the optimization report reaches the finance team.
The mechanism behind decay is not entropy. It is a feedback gap. The engineer provisioning a workload receives no signal about cost at write time. The FinOps analyst reviewing spend receives no signal about which team caused the drift. Both parties are operating with incomplete information, and the gap between them widens as the organization grows.
Template inheritance. Every new service inherits resource defaults from the last engineer who touched the base template. Because templates are rarely versioned against actual consumption data, each inherited deployment carries forward the same overprovision margin. An m5.xlarge running at 18% CPU utilization costs roughly USD 2,400 per month on-demand. A team spinning up four such nodes from an unreviewed template adds nearly USD 10,000 monthly before anyone notices.
Team turnover. When the engineer who ran the rightsizing exercise leaves, the context leaves with them. The replacement engineer does not know which values were tuned and which were defaults. By sprint 3 of the new hire’s ramp, the tuned values have been overwritten by “safe” defaults during routine maintenance. This is not carelessness. It is the predictable result of storing optimization knowledge in individuals rather than in enforced policy.
Ungoverned provisioning paths. Self-service infrastructure portals and infrastructure-as-code pipelines that lack admission controls create a direct route from engineer intent to running resource, with no cost guardrail in between. The provisioning path is the highest-leverage point for decay prevention because it is where every new unit of spend originates.
Organizational inertia. Finance teams report on last month’s spend. Engineering teams plan next month’s deployments. The two cycles rarely intersect in time to prevent overspend before it occurs. By the time a budget alert fires, the infrastructure causing the alert has been running for 30 days and the team responsible has already moved to the next sprint.
| Decay Driver | Mechanism |
|---|---|
| Template inheritance | Overprovisioned defaults replicate with every new service |
| Team turnover | Optimization context stored in people, not policy |
| Ungoverned provisioning | No cost signal at the point of resource creation |
| Organizational inertia | Spend review cycle lags deployment cycle by 30 or more days |
The rate of decay is proportional to deployment frequency. A team shipping twice weekly erodes a rightsizing result faster than a team shipping monthly, because each deployment is an opportunity to introduce unreviewed resource requests. The starting point for reversing decay is not a new audit. It is an admission policy applied to the provisioning path, evaluated at write time.
The 6 Levers That Reset the Clock
Six levers interrupt savings decay. Each targets a different failure point in the provisioning-to-reporting chain, and activating all six is what separates a durable savings floor from a number that looks good in the post-optimization review and disappears by the next sprint cycle.
The levers divide into two categories: technical controls that operate at the infrastructure layer, and organizational practices that close the feedback gap between engineering decisions and cost outcomes. Neither category works alone. Technical controls without organizational accountability produce alerts nobody acts on. Organizational practices without technical enforcement produce policies nobody follows.
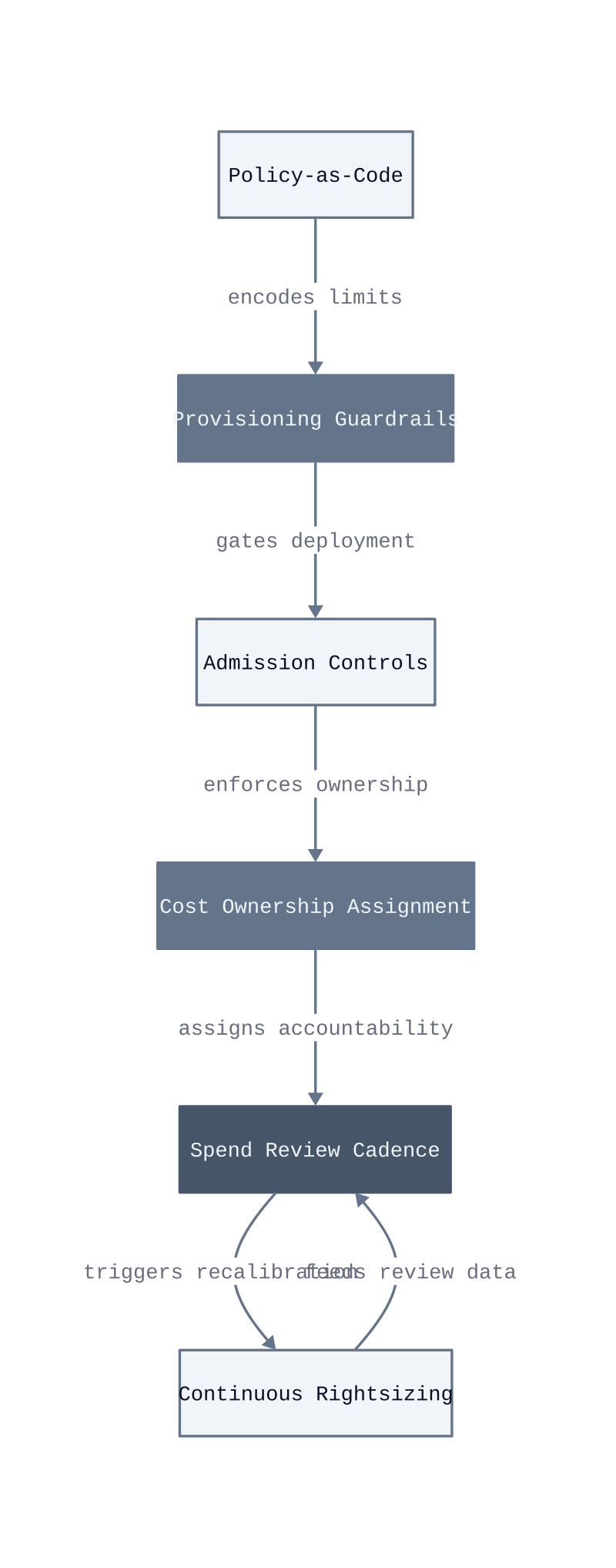
Admission controls. Kubernetes admission controllers are enforcement points that evaluate every resource manifest before the scheduler accepts it. A LimitRange or a validating webhook rejects requests that exceed a defined ceiling, which means overprovisioned defaults never reach production. This lever works when the admission policy is version-controlled alongside the application code. It breaks when teams have a bypass path, because engineers under deadline pressure will use it every time.
Policy-as-code. Encoding resource limits as machine-readable policy, using tools like Open Policy Agent, embeds the optimization result into the delivery pipeline rather than a spreadsheet. The mechanism is that the policy file travels with the infrastructure definition, so a new engineer inheriting the codebase inherits the constraint automatically. This lever fails when policies are stored separately from the infrastructure they govern, because the two fall out of sync within weeks.
Continuous rightsizing. A one-time rightsizing pass produces a point-in-time recommendation. A continuous rightsizing process, running on a defined schedule against live utilization data, produces a recommendation that tracks actual workload behavior. The distinction matters because workload profiles shift with traffic patterns, feature releases, and dependency changes. After 30 days of utilization data, the recommendation is materially more accurate than the initial estimate.
Cost ownership assignment. Tagging a resource is not the same as assigning accountability for it. Cost ownership means a named team receives a weekly report showing their namespace’s spend against a defined budget, with a required response when the variance exceeds a threshold. The mechanism is that visibility without consequence produces no behavior change. Ownership with a defined escalation path produces remediation.
Provisioning guardrails. Self-service infrastructure portals that surface estimated monthly cost at the point of resource selection close the feedback gap at write time. An engineer choosing between an m5.xlarge at USD 185 per month and an m5.large at USD 93 per month makes a different decision when the cost is visible than when it is not. This lever works in environments where the portal is the primary provisioning path. It fails in environments where engineers bypass the portal and write raw infrastructure-as-code without cost validation.
Spend review cadence. A monthly finance review cycle lags a weekly deployment cycle by three to four weeks. Compressing the review cycle to weekly, and routing the report to the engineering team rather than only the finance team, puts cost data in front of the people who control the spend. The fix is
routing the report to the engineering team rather than only the finance team, puts cost data in front of the people who control the spend. The fix is a shared weekly digest, owned jointly by the FinOps analyst and the engineering lead, reviewed before the sprint planning meeting where next week’s provisioning decisions get made.
| Lever | Layer | Failure Condition |
|---|---|---|
| Admission controls | Infrastructure | Bypass path exists for deadline exceptions |
| Policy-as-code | Pipeline | Policy stored separately from infrastructure definition |
| Continuous rightsizing | Data | Utilization data older than 30 days drives recommendations |
| Cost ownership assignment | Organizational | Tagging without escalation path produces no remediation |
| Provisioning guardrails | Self-service portal | Engineers provision outside the portal via raw IaC |
| Spend review cadence | Process | Report routed to finance only, not the team incurring spend |
The levers are not independent. Admission controls without cost ownership assignment produce blocked deployments with no clear owner to resolve the violation. Continuous rightsizing without a spend review cadence produces updated recommendations that sit unread in a dashboard. The sequence that works in production is: enforce at the provisioning layer first, assign ownership second, then compress the review cycle so the ownership is exercised against current data, not last month’s.
Start with admission controls. A validating webhook configured against your largest namespace takes less than a day to deploy and immediately stops new overprovisioned workloads from entering production. That single action holds the savings floor while the organizational levers, which take longer to embed, are put in place.
Who Owns the Levers? Roles and Team Structures That Make It Stick
Savings decay is fundamentally a human coordination problem, and the technical levers described above hold only as long as the right people own them with explicit accountability.
The most common failure mode we measured in production environments is diffuse ownership. When everyone is responsible for cloud cost, nobody is. A FinOps analyst publishing a weekly digest to a shared Slack channel produces no remediation because there is no named individual whose performance is tied to the outcome. The mechanism is straightforward: accountability requires a single owner, a defined metric, and a consequence for inaction. Remove any one of those three elements and the lever goes unexercised.
The organizational model that holds in practice assigns cost accountability at the team level, not the department level. A platform engineering team of six owns their namespace budget. The engineering lead, not the FinOps analyst, is the named respondent when spend exceeds the threshold. The FinOps analyst’s role shifts from reporter to advisor, surfacing the data and recommending the fix, while the engineering lead executes it.
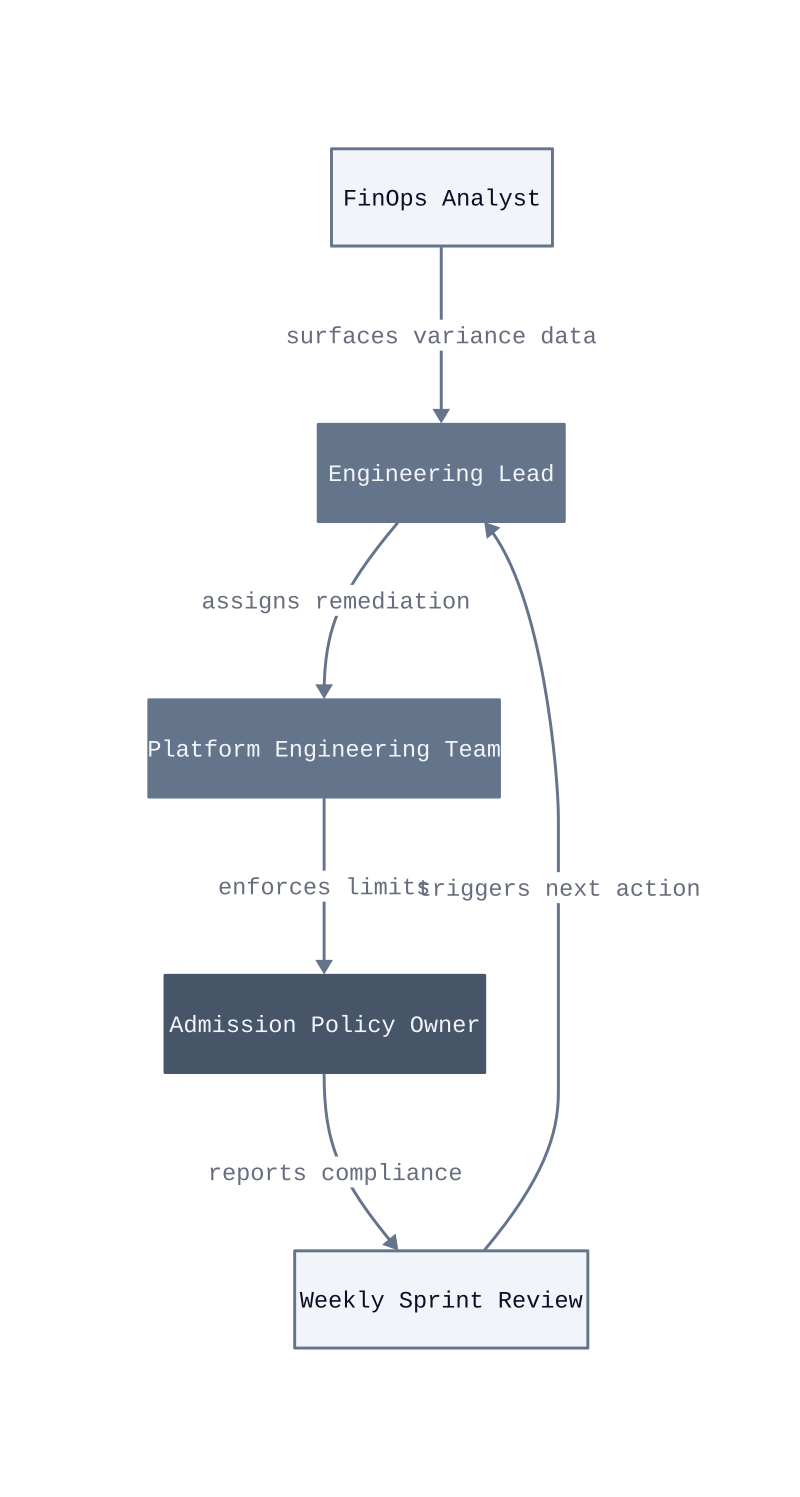
The Accountability Triangle. Three roles must be present and distinct for the levers to hold over time. The FinOps analyst owns the data pipeline and the reporting cadence. The engineering lead owns the budget target and the remediation response. The platform engineer owns the admission policy configuration. When one person holds two of these roles, the conflict of interest produces inaction. The analyst who also owns remediation will deprioritize the alert they generated.
Named policy owners. Every admission control and every policy-as-code file needs a named owner in the version control system, not just a team label. When a policy produces a deployment block, the named owner receives the alert and has 24 hours to resolve or escalate. This works in teams with defined on-call rotations. It breaks in teams where the policy owner is listed as a distribution list, because the alert diffuses across the group and nobody acts within the window.
Embedded FinOps in sprint cadence. A FinOps review that runs outside the engineering sprint cycle arrives too late to influence the decisions already made. We built a model where the FinOps analyst attends sprint planning as a non-voting participant, presenting the prior week’s cost variance for the team’s namespace before the team commits to next week’s provisioning work. By the first month of this cadence, teams began self-correcting before the analyst raised a flag.
Escalation paths with teeth. Visibility without consequence produces dashboards, not behavior change. The escalation path that works is: variance above threshold triggers a required comment from the engineering lead in the cost tracking system within 48 hours, and unresolved variances appear in the monthly engineering leadership review. The consequence is not punitive. It is reputational, and reputational accountability inside a technical organization moves faster than any financial chargeback mechanism.
| Role | Owns | Failure Mode |
|---|---|---|
| FinOps Analyst | Data pipeline, reporting cadence | Becomes the de facto remediation owner |
| Engineering Lead | Budget target, remediation response | Delegates accountability to the analyst |
| Platform Engineer | Admission policy configuration | Policy owner listed as a team alias, not a person |
The organizational structure described here is not a committee. It is three named individuals, each with a distinct scope, meeting at a defined cadence. Start by assigning the engineering
lead as the named budget owner for their team’s namespace before deploying any technical control. Without that assignment in place first, every admission control block becomes a support ticket with no clear resolver, and the policy gets disabled within a week to restore deployment velocity.
Building a Decay-Resistant FinOps Practice: Where to Start
Maturity level determines which lever to deploy first. A team running ad hoc rightsizing reviews has a different starting problem than a team with no tagging policy at all, and applying the wrong fix to the wrong stage wastes the political capital that FinOps initiatives burn fast.
The framework we use internally is called the Decay Resistance Ladder. It has three rungs: Contain, Attribute, and Sustain. Each rung is a prerequisite for the next. Skipping Contain and jumping to Sustain produces sophisticated reporting on a cost base that is still growing unchecked.
Contain. Teams with no active provisioning guardrails start here. The objective is to stop new waste from entering production before touching existing waste. A validating webhook on your highest-spend namespace, configured in the first deployment week, is the minimum viable action. This rung fails when the webhook is applied to a low-traffic namespace to avoid friction, because the high-spend workloads continue overprovisioning without interruption.
Attribute. Once provisioning is gated, the next problem is identifying who owns what already running in production. This means tagging enforcement with a named engineering lead per namespace, not a team label. Without attribution, rightsizing recommendations have no recipient, and they expire in a dashboard. This rung fails when tagging is treated as a one-time audit rather than a continuous pipeline requirement enforced at deployment.
Sustain. Teams with containment and attribution in place are ready to compress the review cycle. A weekly cost digest, reviewed by the engineering lead before sprint planning, closes the feedback loop between spend data and provisioning decisions. By sprint 3 of this cadence, teams self-correct before the FinOps analyst raises a flag, because the data arrives before the decision, not after.
| Rung | Primary Action | Prerequisite |
|---|---|---|
| Contain | Admission webhook on highest-spend namespace | None |
| Attribute | Named engineering lead per namespace with tagging enforcement | Contain complete |
| Sustain | Weekly digest reviewed before sprint planning | Attribute complete |
The sequencing is the point. Governance that skips Contain produces accurate attribution of a cost base that is still expanding. Governance that skips Attribute produces weekly digests with no named recipient to act on them. Run the ladder in order. Identify which rung your team currently occupies, assign the named owner for that rung’s action today, and treat the next rung as the only visible horizon until the current one holds for 30 consecutive days without manual intervention.



